Abstract
Video stabilization is a fundamental and important technique for high quality video. Previously, most of the frame borders were cropped and a moderate level of distortion was introduced. In this paper, frame interpolation is used to reduce jitter between frames. The biggest advantage is that end-to-end training is possible with unsupervised learning. It runs in near real time (15fps).
Intro
As a large amount of video is uploaded on the web, high-quality video is becoming more important and demanding. Many technologies have been explored, and technologies using AI require images unstable video and stable video dataset for supervised learning. Also, most of the frame boundaries must be crop temporarily due to missing views. (Zoom-in effect is always added)
This paper does not perform frame cropping because it uses frame interpolation to stabilize frames. Essentially, the deep framework learns how to create a middle frame between two sequential frames. As a result, spatial jitter is reduced. Also, frame borders are synthesized, so cropping due to missing views is not required.

Related Works
3D method: Model the camera trajectory in 3D space.
2.5D method: Use the partial information of the 3D model.
Both of the above, create a strong stabilizing effect.
2D method: It is performed efficiently and powerfully by applying 2D linear transformation to the video frame.
CNN is a supervised learning method that consists of a set of unstable and stable video pairs and requires labeled data. There is also a video stabilization method using GAN.
Proposed Method

If two frames are given as shown in the picture (b) above, it is warped by halfway. Each frame is warped to create fw-
and fw+ . By supplying this to the U-Net architecture, fint is created. As fw- and fw+ are warped, detailed information is lost, and Blur Accumulation is likely to occur. To prevent this, and , which is an original frame, are supplied to ResNet to create the final f^i.
Unsupervised learning framework
Training scheme
Problems arise when trying to train a model. There is no middle frame. fi , cannot be used as a ground truth because the middle point between adjacent frames fi-1 and fi+1 is not guaranteed. Also, the loss of f^i cannot be determined. Therefore, fs , a spatially translated version of original frame fi is used. Training aims to reconstruct fs by warp fi-1 , fi+1 towards fs . U-Net learns to reconstruct fs given fw- and fw+ , and ResNet does the same thing using fi .
Testing scheme

fi-1 and fi+1 warp towards each other. In fact, given a video sequence, all consecutive frames (fi-1 , fi , fi+1 ) are used as inputs to produce a stable frame output, leaving the first and last frames unchanged. It provides the option of repeatedly executing more frames that have already been interpolated to provide strong visual stability. When repeatedly executed, fi-2 and fi+2 are affected fi^2 .
Loss function
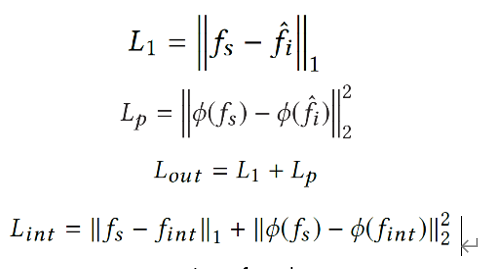
L2 is found to produce blur results, so L1-loss is used. This is the loss of the pseudo-ground truth frame fs and f^i. And, also consider the perceptual loss function utilizing the response. Φ represents the feature vector, and the final Lout is represented by the sum of L1 and Lp . Apply this loss to fint because it speeds up training. Since fint is essentially aiming at fs reconstruction, it is safe to apply that loss.
Implementation
U-Net uses 3 skip connections, includes a 3x3 conv layer, the size of the hidden feature channels is 32, and the
down/upscale is doubled. Finally, fint is created, and original frame fi is warp with fint and input to ResNet. ResNet uses a 1x1 conv layer to minimize noise. And all conv layers use gated conv layers. This is a good way to solve the missing view.
Experiments
Quantitative evaluation
Cropping ratio: Measure the remaining image area after cropping the missing view. The larger the ratio, the smaller the cropping area.
Distortion value: anisotropic scaling of the homography between input frame and output frame.
Stability score: Measures the overall smoothness of the output video.

As a result of deep repeating frame interpolation, the results can produce content at image boundaries that are not visible in that input frame. This paper’s method uses frame interpolation technique for stabilization, so the global image distortion is quite low.
Visual comparison

Compared to the corresponding input frame, all three baselines have some degree of cropping and zoom-in effect, whereas the method in that paper does not cause any cropping or zoom-in effect. The results from that paper appear to have been moved by the camera to stabilize the video frame, creating an invisible area without cropping.
Using the perceptual loss showed marginal improvements in terms of the stabilization metrics (cropping ratio, distortion value, and stability score). In contrast, using the additional perceptual loss showed improvements in visual quality. Due to iterative reconstruction, only using the ℓ1-loss leads to blurry and darker artifacts near the boundaries.
User study

For comparison with commercial algorithms, compared Adobe Premiere Pro CC 2017, Youtube's past stabilizer. Below are the test results consisting of 42 participants for 6
categories (Regular, Crowd, Parallax, Quick Rotation, Running, Zooming). Particularly, in the category with large shaking such as running, the results were superior to other algorithms
Limitations and discussion
As a minor advantage, it is possible to leave instability by adding the number of repetitions and skip parameters. However, blurring can occur at the edges of the image of a video that is severely shaken. Since the original frame is used, most of the frame contents are preserved. Therefore, blur artifacts toward the frame boundary may appear as a result.
Conclusion
Introduced a method of stabilizing without cropping and much distortion. It also supports near real-time calculation speed and is convenient due to unsupervised learning.
'개인 공부 > 논문' 카테고리의 다른 글
| Basic Performance Measurements of the Intel Optane DC Persistent Memroy Module (0) | 2021.05.07 |
|---|---|
| 3-D Stacked Image Sensor With Deep Neural Network Computation (0) | 2021.04.29 |
| LSP Collective Cross-Page Prefetching for NVM (0) | 2021.03.10 |
| Towards Efficient NVDIMM-based Heterogeneous Storage Hierarchy Management for Big Data Workloads (0) | 2021.03.08 |
| The gem5 Simulator (1) | 2021.03.08 |